
I want to convert my ipython-notebooks to print them, or simply send them in html format. I have noticed that there exists a tool to do that already, nbconvert. Although I have downloaded it, I have no idea how to convert the notebook, with nbconvert2.py since nbconvert says that it is deprecated. nbconvert2.py says that I need a profile to convert the notebook, what is it? Does there exist a documentation about this tool?
1,468 5 5 gold badges 19 19 silver badges 25 25 bronze badges asked Apr 14, 2013 at 11:19 1,485 2 2 gold badges 10 10 silver badges 9 9 bronze badges Commented Aug 14, 2020 at 7:51411 k views and no proper solution for simple things such as page breaks - 9 years later still a nightmare!
Commented Jun 12, 2022 at 8:25If you have LaTeX installed you can download as PDF directly from Jupyter notebook with File -> Download as -> PDF via LaTeX (.pdf). Otherwise follow these two steps.
jupyter nbconvert --to html notebook.ipynb
wkhtmltopdf notebook.html notebook.pdf
Original (now almost obsolete) revision: Convert the IPython notebook file to html.
ipython nbconvert --to html notebook.ipynb
answered Sep 19, 2014 at 20:42 5,775 55 55 gold badges 49 49 silver badges 52 52 bronze badges Everything was collapsed into one page -__- Commented May 2, 2018 at 22:23For HTML output, you should now use jupyter in place of ipython e.g. jupyter nbconvert --to html notebook.ipynb
Commented Jul 11, 2018 at 19:45 For this to work, jupyter_contrib_nbextensions should be installed. Commented Feb 5, 2020 at 13:06According to the above answer you need wkhtmltopdf. To install it in ubuntu 14.04 this worked for me gist.github.com/brunogaspar/bd89079245923c04be6b0f92af431c10
Commented Feb 23, 2020 at 6:38 You could also print the website to a pdf. Commented Mar 12, 2020 at 11:23Also pass the --execute flag to generate the output cells
jupyter nbconvert --execute --to html notebook.ipynb jupyter nbconvert --execute --to pdf notebook.ipynb The best practice is to keep the output out of the notebook for version control, see: Using IPython notebooks under version control
But then, if you don't pass --execute , the output won't be present in the HTML, see also: How to run an .ipynb Jupyter Notebook from terminal?
Tested in Jupyter 4.4.0.
answered Dec 12, 2017 at 12:58 Ciro Santilli OurBigBook.com Ciro Santilli OurBigBook.com 374k 114 114 gold badges 1.3k 1.3k silver badges 1k 1k bronze badges Does nbconvert have an option to specify the kernel to use? Commented Mar 2, 2021 at 21:17@HammanSamuel I never touched that, let me know if you find out/ask a separate question and link it here.
Commented Mar 2, 2021 at 21:33 RuntimeWarning: coroutine 'ZMQSocketChannel.get_msg' was never awaited Commented May 20, 2022 at 5:46answered Apr 14, 2013 at 11:30 79.6k 25 25 gold badges 109 109 silver badges 120 120 bronze badgesIf you want to provide others with a static HTML or PDF view of your notebook, use the Print button. This opens a static view of the document, which you can print to PDF using your operating system’s facilities, or save to a file with your web browser’s ‘Save’ option (note that typically, this will create both an html file and a directory called notebook_name_files next to it that contains all the necessary style information, so if you intend to share this, you must send the directory along with the main html file).
Thank you! The HTML version is really good, and really simple to obtain. However the PDF isn't good, the graphs are cut in two pieces if they are between two pages and the long code line are cut too.
Commented Apr 14, 2013 at 11:39@nunzio13n -- Well at least you have the html. I haven't used nbconvrt so I can't really help you on that. Hopefully someone who has will come along.
Commented Apr 14, 2013 at 11:55 Using print in your browser by using CTRL + P works. Commented Apr 26, 2020 at 0:28a) Exporting as HTML from Jupyter does not seem to save pictures, b) File -> save as form Firefox gets you a completely uninteractive page that only shows what's visible. Also the link in your post is now dead.
Commented Jan 5, 2021 at 16:36nbconvert is not yet fully replaced by nbconvert2, you can still use it if you wish, otherwise we would have removed the executable. It's just a warning that we do not bugfix nbconvert1 anymore.
The following should work :
./nbconvert.py --format=pdf yourfile.ipynb If you are on a IPython recent enough version, do not use print view, just use the the normal print dialog. Graph beeing cut in chrome is a known issue (Chrome does not respect some print css), and works much better with firefox, not all versions still.
As for nbconvert2, it still highly dev and docs need to be written.
Nbviewer use nbconvert2 so it's pretty decent with HTML.
List of current available profiles:
$ ls -l1 profile|cut -d. -f1 base_html blogger_html full_html latex_base latex_sphinx_base latex_sphinx_howto latex_sphinx_manual markdown python reveal rst Give you the existing profiles. (You can create your own, cf future doc, ./nbconvert2.py --help-all should give you some option you can use in your profile.)
$ ./nbconvert2.py [profilename] --no-stdout --write=True
And it should write your (tex) files as long as extracted figures in cwd. Yes I know this is not obvious, and it will probably change hence no doc.
The reason for that is that nbconvert2 will mainly be a python library where in pseudo code you can do :
MyConverter = NBConverter(config=config) ipynb = read(ipynb_file) converted_files = MyConverter.convert(ipynb) for file in converted_files : write(file)
Entry point will come later, once the API is stabilized.
I'll just point out that @jdfreder (github profile) is working on tex/pdf/sphinx export and is the expert to generate PDF from ipynb file at the time of this writing.
community wikiThank you, you have clarified more of my doubts. But still nbconvert2.py doesn't work, because it need even a Config file [NbconvertApp] Config file for profile './profile/latex_base.nbcv' not found, giving up And nbconvert doesn't give me directly a pdf file, but a latex file, and I have to process the *.tex file with pdflatex, but it is a good solution.
Commented Apr 14, 2013 at 13:30Probably it isn't a issue of nbconvert but, it is due to my lack of knowledge about. Perhaps when the documentation comes out all will be clear, ipython with the notebook and nbconvert are a very nice work and I'm sure that will be a documentation soon.
Commented Apr 14, 2013 at 18:38This seems to lose/not give any ipython numbering (was hoping it would convert using the ipython directive).
Commented Jan 18, 2014 at 4:22Is there an API version to make this happen? I see that there is IPython.nbconvert.exporters.latex and I wonder if there is a way to get PDF output from this without the command line tool. Also, what are the dependencies to get it to work? (pandoc, tetex, other things?) And I assume it isn't cross platform (won't work on Windows). TIA!
Commented Jun 30, 2014 at 15:48 2,967 24 24 gold badges 48 48 silver badges 69 69 bronze badges answered Dec 12, 2018 at 18:10 user9522821 user9522821 It is advisable to expand all the output cells. So the PDF will be clear. Commented Nov 24, 2020 at 6:13Only this answer would be useful to you if you have math, scientific formulae in your document. Even if you don't have them it works fine.
GUI way
Command-Line way
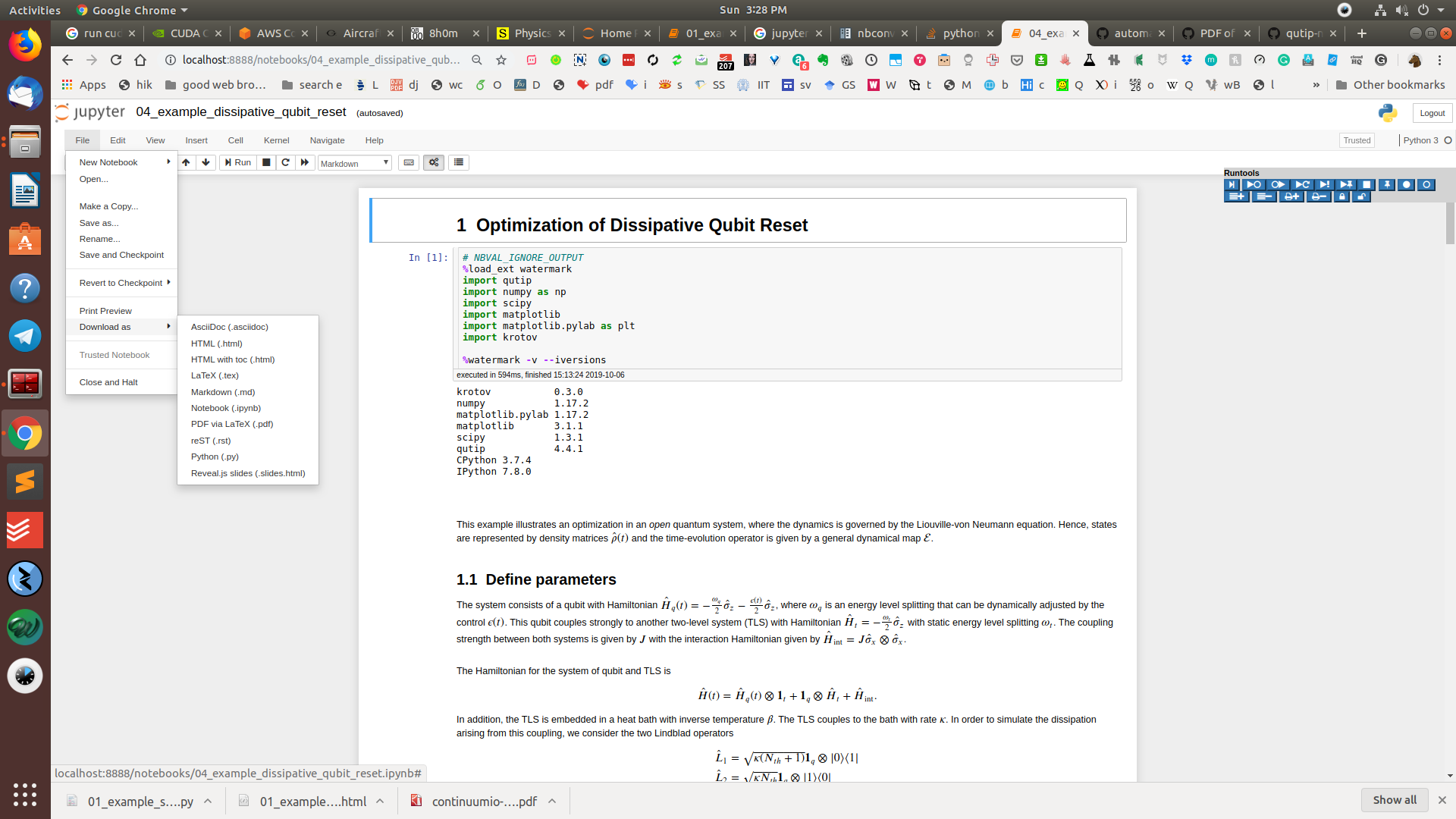
If you are using sagemath cloud version, you can simply go to the left corner,
select File → Download as → Pdf via LaTeX (.pdf)
Check the screenshot if you want.
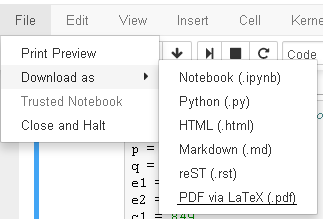
If it dosn't work for any reason, you can try another way.
select File → Print Preview and then on the preview
right click → Print and then select save as pdf.
You can do it by 1st converting the notebook into HTML and then into PDF format:
Following steps I have implemented on: OS: Ubuntu, Anaconda-Jupyter notebook, Python 3
After execution will create HTML version of your notebook and will save it in the current working directory. You will see one html file will be added into the current directory with your_notebook_name.html name
Note that from print option we also have the flexibility of selecting a portion of a notebook to save in pdf format.
1 1 1 silver badge answered Feb 28, 2019 at 3:57 Yogesh Awdhut Gadade Yogesh Awdhut Gadade 2,668 26 26 silver badges 19 19 bronze badgesThanks for the answer. How can I specify a file path to write instead of the current working directory?
Commented Jan 27, 2022 at 11:01 Found it here: stackoverflow.com/a/43475653/13968392 Commented Jan 27, 2022 at 11:27Easy Direct way Just
1-Click Ctrl + P while you inside Jupiter notebook
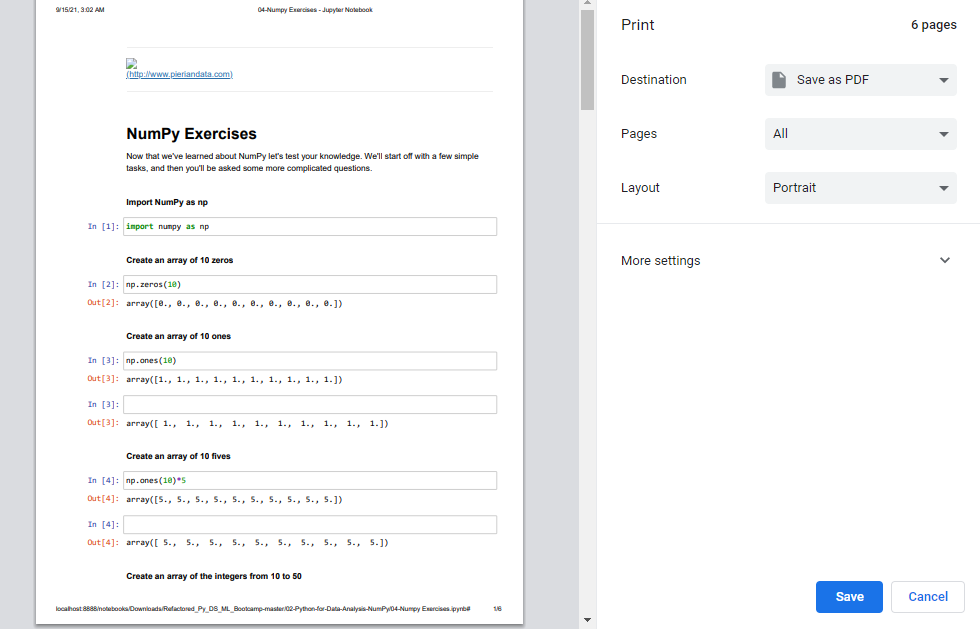
2-Save as PDF
answered Sep 15, 2021 at 1:03 1,460 1 1 gold badge 18 18 silver badges 19 19 bronze badgesFor me.. this is by far the best answer. Spent ages trying to get nbconvert to work and still no luck.
Commented May 3, 2022 at 11:11I find that the easiest method to convert a notebook which is on the web to pdf is to first view it on the web service nbviewer. You can then print it to a pdf file. If the notebook is on your local drive, then upload it to a github repository first and use its url for nbviewer.
answered Apr 5, 2018 at 1:28 41 2 2 bronze badgesThe plain python version of partizanos's answer.
import os [os.system("jupyter nbconvert --to pdf " + f) for f in os.listdir(".") if f.endswith("ipynb")] Using --template report as an additional option compiles also a ToC to the resulting pdf by taking the different markdown headings in the notebook.
Commented Jun 13, 2020 at 7:15For those who can't install wkhtmltopdf in their systems, one more method other than many already mentioned in the answers to this question is to simply download the file as an HTML file from the jupyter notebook, upload that to HTML to PDF, and download the converted pdf files from there.
Here you have your IPython notebook (.ipynb) converted to both PDF (.pdf) & HTML (.html) formats.
answered Feb 11, 2020 at 15:13 Shayan Shafiq Shayan Shafiq 1,468 5 5 gold badges 19 19 silver badges 25 25 bronze badgesI've been searching for a way to save notebooks as html, since whenever I try to download as html with my new Jupyter installation, I always get a 500 : Internal Server Error The error was: nbconvert failed: validate() got an unexpected keyword argument 'relax_add_props' error. Oddly enough, I've found that downloading as html is as simple as:
No print preview, no print, no nbconvert. Using Jupyter Version: 1.0.0 . Just a suggestion to try (obviously not all setups are the same).
answered Nov 13, 2017 at 22:02 semore_1267 semore_1267 1,417 3 3 gold badges 16 16 silver badges 30 30 bronze badgesI combined some answers above in inline python that u can add to ~/.bashrc or ~/.zshrc to compile and convert many notebooks to a single pdf file
function convert_notebooks()answered May 7, 2019 at 23:28 partizanos partizanos 1,104 13 13 silver badges 23 23 bronze badges
python -m pip install notebook-as-pdf pyppeteer-install
You can also use it with nbconvert:
jupyter-nbconvert --to PDFviaHTML filename.ipynb
which will create a file called filename.pdf.
or pip install notebook-as-pdf
create pdf from notebook jupyter-nbconvert-toPDFviaHTML
answered Jun 28, 2020 at 18:33 Dhiren Biren Dhiren Biren 510 4 4 silver badges 8 8 bronze badgesThank you, this worked well for me. I first tried this within a Python 3.6.8 environment but ran into some issues. I then upgraded to a Python 3.7.8 environment, based on Conda, and it worked like a Charm.
Commented Aug 2, 2020 at 19:18That is because asyncio is a dependency for the package, and somewhere in the code there is an asyncio.run which is a 3.7 only method.
Commented Aug 4, 2020 at 23:42Other suggested approaches:
Solution: A better, hassle-free option is to use an online converter which will convert the *.html version of your *.ipynb to *.pdf.
Steps:
I can't get pdf to work yet. The docs imply I should be able to get it to work with latex, so maybe my latex is not working.
$ ipython --version 1.1.0 $ ipython nbconvert --to latex --post PDF myfile.ipynb [NbConvertApp] . raise child_exception OSError: [Errno 2] No such file or directory $ ipython nbconvert --to pdf myfile.ipynb [NbConvertApp] CRITICAL | Bad config encountered during initialization: [NbConvertApp] CRITICAL | The 'export_format' trait of a NbConvertApp instance must be any of ['custom', 'html', 'latex', 'markdown', 'python', 'rst', 'slides'] or None, but a value of u'pdf' was specified. However, HTML works great using 'slides', and it is beautiful!
$ ipython nbconvert --to slides myfile.ipynb . [NbConvertApp] Writing 215220 bytes to myfile.slides.html Update 2014-11-07Fri.: The IPython v3 syntax differs, it is simpler:
$ ipython nbconvert --to PDF myfile.ipynb In all cases, it appears that I was missing the library 'pdflatex'. I'm investigating that.